Hoe leren mensen taal? Kinderen leren hun moedertaal vanzelf. Als je op latere leeftijd een taal leert, komen daar grammatica en woordenboeken bij kijken.
Hoe kunnen computers met taal omgaan? De klassieke Natural Language Processing (van vóór ChatGPT) werkt een beetje zoals mensen op latere leeftijd een taal leren. Geef de computer een lijstje zelfstandige naamwoorden om te herkennen herkennen, werkwoorden, regels voor vervoegingen, woordvolgorde, en nog wat regels…. En je bent tientallen jaren bezig om het een beetje werkend te krijgen. Met nadruk op een béétje. Daarom was ChatGPT zo’n enorme verrassing voor iedereen. AI kan tegenwoordig een heel behoorlijk gesprek voeren. Large Language Models, de vorm van AI die zorgt dat je met ze kunt ‘praten’, leren taal zónder grammatica en woordbetekenissen. Hoe kan dat?
Topografie en grammatica
We leerden op school niet alleen vreemde talen. Er waren ook vakken zoals aardrijkskunde. Topografie! Het kwam er op neer dat we kaarten uit ons hoofd leerden. Dat is vandaag niet meer nodig. Navigatiesystemen leiden ons feilloos van A naar B. Google Maps, TomTom en zijn vriendjes hebben topografie geleerd zoals wij vreemde talen leerden: met lijstjes en regels. Welke plaatsen zijn er? Welke verbindingen (wegen) zitten ertussen? Waar mag je rijden en hoe hard? Een heel werk! Wat als dat we die lijstjes en regels niet hebben? Wat als we geen wegenkaart bij de hand hebben?
Ik leerde als kind de kaart van mijn eigen dorp door er elke dag doorheen te wandelen en te fietsen. Als je als volwassene naar een andere stad of zelfs een ander land verhuist is dat veel moeilijker. Net zoals je moedertaal vanzelf gaat en Duitse naamvallen niet (voor Nederlanders dan).
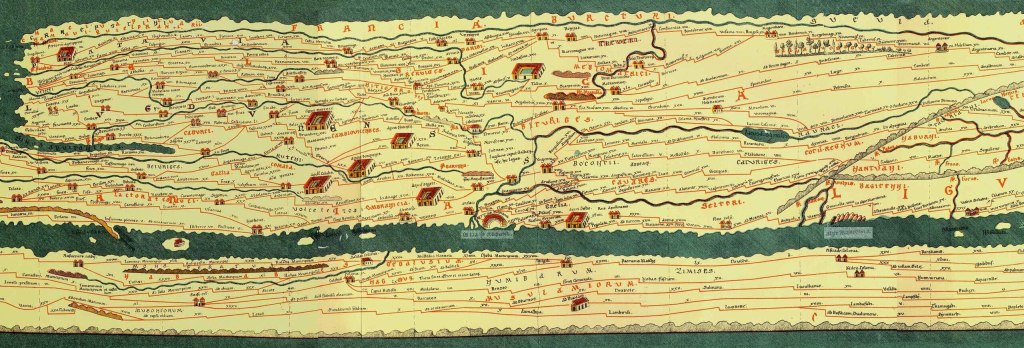
Een Romeinse bezoeker
Stel je voor dat er een tijdreiziger op bezoek komt, laten we (in plaats van die Middeleeuwer uit mijn eerste blog) eens een Romeinse cartograaf uitnodigen. Die kent Nederland niet. Ook heeft hij geen flauw benul van moderne transportmiddelen. Maar als cartograaf wil hij wel graag leren hoe Nederland in elkaar steekt. Je nodigt familie, vrienden, buren en collega’s uit om je Romeinse gast over de topografie van Nederland te vertellen. (Gelukkig kan Google Translate ook Latijn vertalen.)
Dag in dag uit worden er reisverhalen verteld: van Maastricht via Nijmegen naar Utrecht. Van Groningen via Zwolle en de polder naar Amsterdam. Van Leeuwarden via Sneek, IJlst, Sloten, Stavoren, Hindeloopen, Workum, Bolsward, Harlingen, Franeker, Dokkum terug naar Leeuwarden. Van Zurich naar Den Oever. Etcetera.
Je Romeinse vriend hoort al die verhalen aan en krijgt na verloop van tijd een indruk van de topografie van Nederland. Op basis van de gerapporteerde reistijden tussen plaatsen kan onze Romein waarschijnlijk met wat gepuzzel de plaatsen wel zo op een vel papier tekenen dat de plaatsen en wegen globaal kloppen met alle reisverhalen.
Het leuke is: zo zijn er daadwerkelijk kaarten gemaakt. De befaamde Tabula Peutingeriana is een kaart van Europa die vooral gebaseerd is op de manier waarop steden met elkaar verbonden waren via handelsroutes en pelgrimsroutes. De vorm klopt niet echt met hoe wij Europa tegenwoordig zien, maar voor het doel werkte de kaart wel.
Een Romeinse kaart van Nederland
Onze Romein, laten we hem Gaius Publius Tiberius noemen, zal zijn kaart op twee dimensies baseren: horizontaal en verticaal, X en Y, noord-zuid en oost-west. Als de kaart nauwkeuriger moet, kan hij nog dimensies toevoegen. Behalve locaties van plaatsen en hun verbindingen kun hij ook nog een getal toevoegen dat het soort verbinding aangeeft: voetpad, fietspad, weg, snelweg… misschien ook nog kanaal, veerpont, luchtverbinding.
Gebaseerd op de reisverhalen, kan een beetje slimme Gaius kan dit allemaal uitvogelen zonder te weten welke soorten transport er in onze tijd bestaan. Sommige reizen kosten namelijk 30 minuten om van Den Haag naar Utrecht (via Zoetermeer, Gouda en Woerden) te komen. Dat zal wel een snelweg zijn, ook al weet Gaius niet wat dat is. Sommige reizen kosten veel meer tijd: van Pieterburen naar de Sint Pietersberg kost 26 dagen – althans volgens de reisverhalen. Dat tempo is duidelijk geen snelweg en zal voor Gaius veel bekender voorkomen. De Romein komt met een kaart waarop de plaatsen redelijk nauwkeurig ingetekend zijn, met wegen ertussen die een indicatie geven hoe snel je tussen die plaatsen kunt reizen.
Je kunt een taalmodel op vergelijkbare manier maken door enorm veel tekst, de trainingsdata, aan een computer te geven. Elke tekst en elke zin is dan als het ware een ‘reisverhaal’: de woorden daarin staan in een bepaalde volgorde. Welk woord volgt meestal op welk ander woord, gegeven alle voorgaande woorden? Als je dat goed genoeg in kaart gebracht hebt, kan ChatGPT op jouw vraag een ‘logisch’ antwoord geven. Merk op: zónder dat de computer ‘weet’ wat een woord in het echt betekent!
Je zult niet genoeg hebben aan alleen maar verbindingen tussen plaatsen – je wilt ook wijken en adressen.
Dat doen taalmodellen ook: ze gebruiken geen woorden maar ‘tokens’, wat een deel van een woord is. Taalmodellen houden daarnaast ook bij welke woorden en zinnen op grotere afstand van elkaar vaak samen voorkomen en welke combinaties essentieel zijn. Dit is het ‘attention’ mechanisme, daarover later wellicht meer. Net zoals er vaak gereisd wordt tussen Den Haag en Amsterdam, maar dat het dan voor de logica van de reis minder belangrijk is of je de A44 of de A4 pakt – behalve als je meer meeneemt dan alleen de afstanden, zoals files.
Hoe ziet die taalkaart eruit?
Net zoals Gaius alle plaatsnamen van Nederland met getalletjes kon weergeven (positie op de kaart), kun je zo alle woorden van een taal ook in getalletjes vangen. Gaius had zelf natuurlijk al wel bedacht dat plaatsen een X en een Y hebben, het was daarna vooral een kwestie van puzzelen. De fascinerende truuk van Large Language Models is dat we die helemaal niet hoeven te vertellen welke getallen die kan gebruiken om woorden ‘op de kaart te zetten’.
Door middel van ‘deep learning’ kan de AI zelf bepalen welke getallen het best gebruikt kunnen worden om woorden op zijn interne kaart in te tekenen.
Deep learning is geïnspireerd op de manier waarop het menselijk brein werkt: verbindingen tussen neuronen die sterker of zwakker worden. Het deep learning model wordt getraind door een grote hoeveelheid kleine deelberekeningen uit te voeren op je input, de trainingdata. De uitkomst van het model, zeg maar de nauwkeurigheid van de kaart, zal in het begin niet kloppen met de vertelde reisverhalen. Door kleine correcties in al die deelberekeningen door te voeren (verbindingen tussen neuronen versterken of verzwakken) gaat het eindresultaat steeds beter lijken op wat het moet zijn. Als je maar genoeg trainingdata hebt en daarvan de gewenste uitkomst weet, kun je het model uiteindelijk zo goed laten functioneren dat het geen fouten meer maakt. In ieder geval niet voor de bekende trainingsdata.
Wie nog wat dieper op deep learning wil ingaan en een heel klein beetje wiskunde achter de hand heeft, zou deze briljante introductie eens moeten lezen: Hello Deep Learning: Intro – Bert Hubert’s writings
Dit is wat in de wandeling ‘zelflerend’ wordt genoemd. Maar hoe kun je dat dan met taal doen? Dan heb je alleen maar enorme hoeveelheden teksten. Hoe kun je dan zeggen ‘dit is goed, dat is fout’? Een slimme truuk is dat je het model dan vraagt om ‘het volgende woord in de zin’ te leren voorspellen. Je weet namelijk uit de trainingsdata natuurlijk wat het volgende woord echt moet zijn. Daarom worden LLM’s ook wel ‘woordvoorspellers’ genoemd.
Er zit alleen één groot nadeel aan deze hele methode: je hebt echt heel veel trainingsdata nodig. Echt veel. Daarom duurde het ook zo lang voordat de deep learning methode ook echt tot resultaten leidde.
Large Language Models maken dus hun eigen ‘kaart’ van een taal. Op basis van al hun trainingdata hebben ze een statistisch model van de populariteit van woorden, zinnen en allerlei combinaties daarvan. Als je onder de motorkap van zo’n model kijkt en de ‘kaart’ probeert te interpreteren, zie je in sommige gevallen herkenbare relaties. Een veel gebruikt voorbeeld is “koning – man + vrouw = koningin”, alhoewel het in de praktijk wel een beetje te mooi is om helemaal waar te zijn. Toch blijkt het wel zo te zijn dat je patronen kunt zien die overeenkomen met wat abstractere ideeën, zoals onderzoekers van Anthropic lieten zien: ze konden bijvoorbeeld de concepten ‘programmeerfout’, ‘seksisme’ of ‘geheimhouding’ vrij goed terugzien.
Hoe helpt deze vergelijking?
Het is goed om te onthouden dat een Large Language Model zoals in ChatGPT een heel uitgebreide taalkaart heeft en daar met zijn ‘navigatieapp’ min of meer logische reizen in uitstippelt. We kunnen lachen om mensen die hun navigatiecomputer blind vertrouwen en héél bijzondere routes nemen, maar we moeten ons realiseren dat je ook uit ChatGPT heel rare teksten kunt halen.
Ook goed om te weten dat de kaart van Gaius Publius Tiberius gebaseerd is op reisverhalen en niet op waarnemingen ter plekke. Op dezelfde manier: het taalmodel is gebaseerd op trainingsdata en weet dus niet echt hoe de werkelijkheid eruit ziet. Het is een aardig bijeffect dat er allerlei wereldkennis opduikt maar het blijft in essentie slechts een kaart.
Er zijn nog veel meer vragen. Heeft Gaius wel álle reisverhalen gehoord? Heeft het taalmodel wel álle soorten Nederlands gezien? Daarover later meer.
Zoals George Box het zo mooi zei: “alle modellen zijn fout, maar sommige zijn nuttig”.

Plaats een reactie